
Simulation Reproducibility
[!note] 📄 30 Second Summary: The overriding principle for improved engineering analysis and simulation is that everything is code → a report is code, analysis is code, code is code! And the software engineering industry are miles ahead with version control, unit testing, automated workflows, reproducibility, virtual environments, etc, etc.
Introduction
Finite element analysis and engineering simulations can be notoriously challenging to manage, with whole books dedicated to the verification and validation of engineering results obtained from simulation.
Even in the simplest sense of being able to revisit an analysis (even your own) some months in the past is difficult and confirm that you can reproduce the previous results is not a given. Add more time, or an analyst that’s not your past self, and it is even harder.
In the broadest sense this issue of reproducibility might be called Configuration Management, but that is too broad to enable us to pose the problem in a way that is tractable.
I’ve previously written about the benefits of managing analysis workflows (Snakemake Analysis Workflow Management) and in being able to automate analysis reports (Automated Workflow Report).
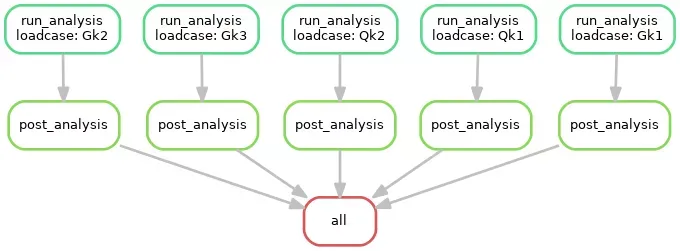
What is the problem we’re trying to solve?
By bounding the context to be engineering analysis and reproducibility we are trying to solve the following:
- Being able to easily compare two version of an analysis
- Being able to rerun an old analysis with minimal effort and exactly reproduced results
- Understanding provenance of work (knowing what dependencies might have changed)
There are some implicit pitfalls that we all know exist and are wrapped up in the above - things like it’s a bad idea to manually copy-paste from one application to another, that any manual step is error-prone due to human fallibility, that complex dependencies are bad, etc.
Principles for engineering analysis
This leads me to the following principles for improved engineering analysis / simulation:
- Reproducibility — The entire set of queries, transforms, visualisations, and write-up should be contained in each contribution and be up to date with the results. The entire workflow is code. Workflow management becomes central. Environment management (e.g. docker, virtual environments, virtual machines) is also of vital importance to being able to rerun and faithfully reproduce analysis results many years later.
- Quality — No piece of analysis should be shared without being reviewed for correctness and precision. Provenance should be guaranteed (by the nature of an automated workflow). Version control, continuous integration and code quality (e.g. linting, unit testing, static checking) become the mechanisms for ensuring quality.
- Consumability — The results should be understandable to readers besides the author. Visualisations and interactive graphics can help communicate key points. The results should be able to be rerun with minimal effort.
In summary, these principles are lifted straight from the software development industry - and for good reason - there is no other way to manage hugely complex software development than by following the principles above. Tomorrow’s simulation engineers will have to learn things the software industry have been doing for years - like version control, continuous integration, unit testing, automation, etc.
Proposed solutions options
To solve the above problems, we can use the mental model or paradigm that everything is code. What I mean by this is that the entire simulation workflow, from model, to applying loads and boundary conditions, to solving, to generating and interpreting results, can be considered as code, that is statements of reproducible and testable steps that a computer can run.
There are key points here:
- That everything is code → computer code provides specific, repeatable steps. There is no manual set, copy-paste errors, etc. that can be introduced if we think of all analysis steps are being able to be deconstructed into code.
- That an analysis is a workflow → a workflow being a series of steps where we are mutating from one state to another state as stepping-stones to the final output. The important thing here is that the workflow doesn’t stop when the analysis is run and results are in the software package, but extends to the interpretation of the results and the reporting of them in (typically) an analysis report.
And now to look back at the principles, the following solution options are proposed:
- Reproducibility
- Environment Management: virtual environments (conda, venv), docker, singularity, vagrant and Virtual Machines (VMs), R Packrat
- Workflow Management (provenance):
- Analysis: workflow as code, automated steps. Snakemake, SoS, R Drake, nextflow, make
- Reporting: Markdown, RMarkdown, Pandoc
- Quality 3. File Management: version control. Git, collaboration, issue tracking 4. Code Quality: static checking, unit testing, continuous integration, testing code coverage
- Consumability 5. Folder Management: cookie cutter templates 6. Documentation: document everything in detail as you go 7. Interactive charts: bokeh, plotly,
Current blockers
There is no smooth path towards analysis workflows and reproducible simulations. Here are some initial blockers that I think need to be overcome:
- Simulation analysts don’t tend to use databases. Databases have been mainstream in the software world for decades, and yet analysts are not familiar with them and would tend to default to Excel.
- There is a dominance of proprietary analysis software, which makes integrating into an analysis workflow harder.
Further thoughts
There is also something about collaboration - collaboration across engineering disciplines, avoiding siloed working, and the democratisation of skills that were once in the hands of a few irreplaceable specialists. Linked to this is the broader topic of Knowledge Management, where discoverability is also important (so anyone can find, navigate, and stay up to date on the existing set of work on a topic or domain) and learning so that other analysts and engineers can expand their abilities with tools and techniques from others’ work. When analysis and the entire reporting workflow is code, and when that code is reproducible, then others can learn and extend the application. This makes knowledge management and integral part of using analysis workflows.
If you enjoyed this post, you may also like to check out my ANSYS user guide: